Whitespace and comment tokens#387
Conversation
for us this only changes the @nogc not being there anymore. This allows for more control within TokenStructure aliases to create GC dependent functions for example.
1c4eb5b to
081566a
Compare
This replaces the previous comment and trailingComment properties. Maintains full feature backwards-compatibility, only some `@nogc` code may now fail to compile if it used the comment or trailingComment properties from Token. supersedes dlang-community#149
081566a to
db2a669
Compare
|
also nice change that was introduced alongside: Error messages containing the Token type are now much more readable: |
|
I think the |
Codecov Report
@@ Coverage Diff @@
## master #387 +/- ##
==========================================
+ Coverage 75.53% 76.09% +0.55%
==========================================
Files 8 9 +1
Lines 6985 7123 +138
==========================================
+ Hits 5276 5420 +144
+ Misses 1709 1703 -6
Continue to review full report at Codecov.
|

|
When we tag a release with these changes we should change the version number to |
|
I was trying to update phobos to use the latest dscanner [1], that in turn was updated to use the latest libdparse and stumbled into the same failure as @MoonlightSentinel. I lost a few hours investigating the failure and ended up at this same PR. How can we fix this issue? It is currently blocking the phobos PR queue. Also, we should be testing new additions against phobos (via dscanner) just to make sure that future additions do not break it. |
|
@WebFreak001 any ideas for a fix? |
|
So the exception itself is legit, because for some reason one of the comment is garbage: Removing code / comments makes the location move. It reeks of memory corruption. Which is either a 4 bytes pattern or an This doesn't evoke anything obvious to me (perhaps indexes in the file?) but there is a clear pattern. BTW while looking at the code I noticed this change: |
|
@WebFreak001 could you provide some assistance? |
|
I think what Mathias said is already gonna be the issue - as this only happens with huge files it's probably either something with slices of data that has moved (source code as moved and the appender didn't dup the code) or there was previously an issue in DCD with a splitting list data structure that was fundamentally flawed somehow, but had such a big threshold that it never observed in smaller files. |
|
I have tried the zip here and a complete phobos checkout using Also tried compiling D-Scanner with LDC in release build Also tried make Got the issue now, forgot the --config parameter |
|
OK so the strings of the trivia parts are all fine in memory - the combined cached string gets overwritten by the GC (in my case I had it that std.regex was doing some allocation and the GC gave it part of that memory) which causes the error. When the comment (string) is first assigned in parser.d in parseFunctionDeclaration the content is correct, later the same string data pointer however causes the UTFException and is no longer correct. To me this seems like the GC either loses track of this string (thinking it's not allocated) or it's wrongly allocated.
|
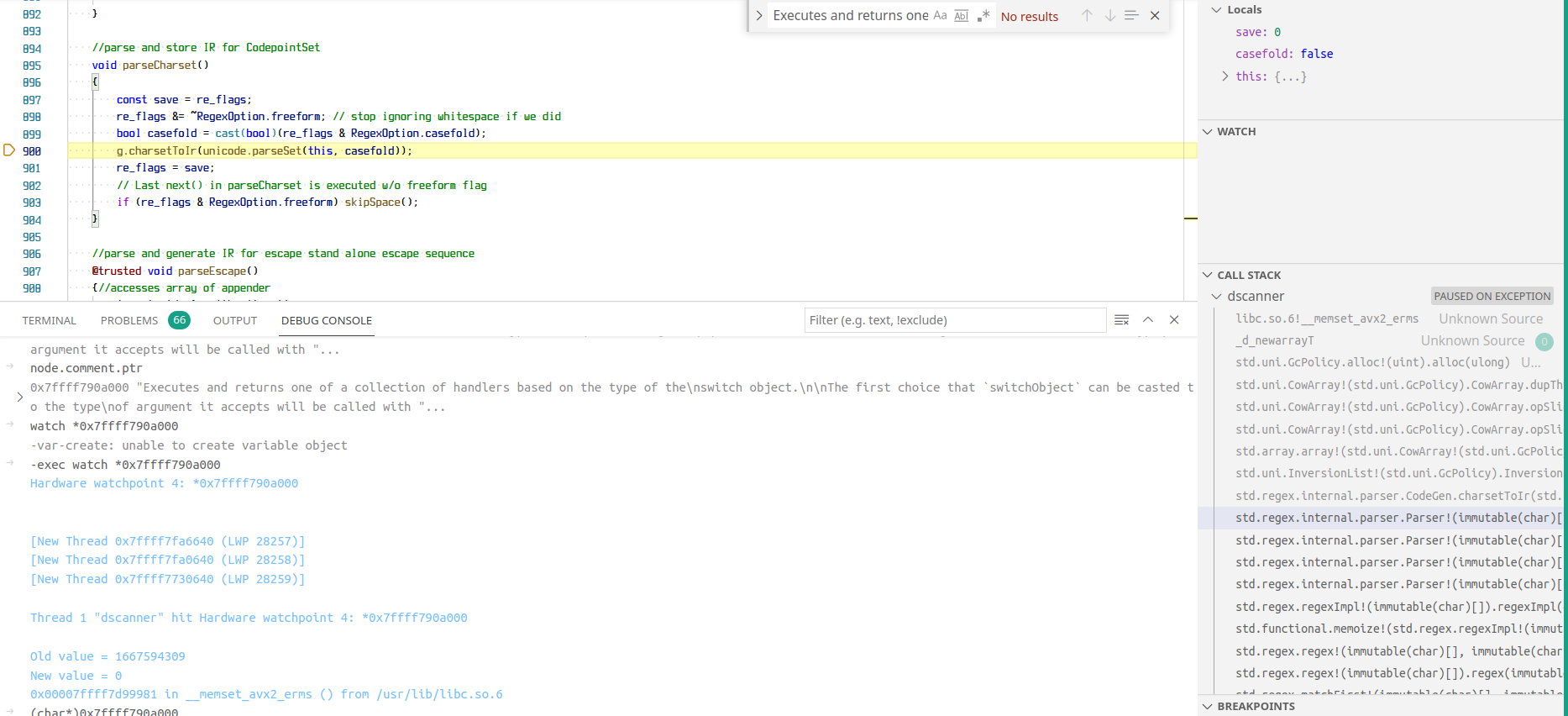
|
I found one issue by accident just now: The comment bytes are cast to string without interning (because of the Maybe we shouldn't override what the user provides? Although before it should have happened too, seems like the increased memory usage now might be the cause for the code now being freed while it wasn't before. This is not a fix for the issue, but rather prevents issues with trying to access comments later appearing. This seems to have made the original issue trigger even earlier (on an earlier token) in analyzing - indicating that it might be relevant how much memory is allocated. The weird thing is that it is the string returned by Fun fact: |
|
maybe the comment generation should use the normal StringCache and be generated beforehand instead of lazily computing it when needed? |
Could it be that the pointer for the data is not aligned, causing the GC to miss it ? |
|
The data is allocated by appender so the address should be allocated. The string itself holding the pointer value to that data is inside a Token structure, which doesn't do special alignments. Here are the definitions however: libdparse/src/std/experimental/lexer.d Line 331 in fbdf71b Line 146 in fbdf71b These tokens are themself an array, allocated by an appender in Line 480 in fbdf71b I don't know, does appender remove the alignment? Otherwise it would all be aligned well. So the data is stored like this:
|
|
Until we get to the bottom of this, would it make sense to revert this PR and update Dscanner so that the phobos AliasAssign PRs get unblocked? |
|
I think it might be better to leave this API in as this has been in for 3 releases now already. As a workaround it might be possible to call internString on the appender-allocated string to make it actually permanent in memory. |
|
Would setting |
|
the comments of the tokens are not corrupting, they are staying fine as they are already interned (at least also did the tests using this option) - the thing that is corrupting regardless is the memoized comment/trailingComment in https://github.com/dlang-community/libdparse/pull/387/files#diff-073a681f37b7ac58a75cb15be50882a5075a2ebcaa53efc4bd97cffa037ab6ddR146 that is created using an appender. When the string is assigned to another variable in the parser.d FunctionDeclaration it's still valid, however a little later it gets corrupted. |
Fix: #445 |
This replaces the previous comment and trailingComment properties. Maintains full feature backwards-compatibility, only some
@nogccode may now fail to compile if it used the comment or trailingComment properties from Token.Creates a new trivia.d file which contains helpers to deal with trivia and moves the previous comment helper in lexer.d into this file.
Simplifies getTokensForParser implementation too.
I suggest looking at each commit separately, they are strictly separated in functionality.
Commit
add unittest for current comment behavior(15e117a) just adds unittests to the previous behavior, it passed how it was that way.Commit
separate comment helpers into dparse.trivia(afe19b2) moves the comment helper structs to dparse.trivia, also copies an internal function and enum which was previously inside the getTokensForParser functionCommit
make token attributes not apply to extraFields(4d93669) moves the extraFields mixin outside the@safe nothrow pure @nogcblock, so it can decide on the attributes itself - this may introduce changes in other software using std.experimental.lexer as it weakens attributesCommit
attach whitespace & comment tokens to tokens(db2a669) does the actual changes: remove comment parsing from the getTokensForParser function, instead append trivia (almost the same logic, just simpler), adds compatibility getters to the Token struct and unittests a big block of trivia heavy codeSupersedes #149